非你网
Search
category
Python
python求交集的几个方法
python怎么求交集呢。如果是DataFrame某字段求交集,可以用isin,也可以用merge。isin只会保留一边...
Post on 2017-01-04
790
0
Python
python插入数据到mysql效率
python插入数据到mysql的工具很多。每个工具写法不一样效率也不一样。就拿sqlalchemy,MySQLdb,s...
Post on 2017-01-04
854
0
Python
SQLAlchemy,ORM方式插入数据,重复跳过
避免往数据库中插入重复数据,可以使用INSERT IGNORE 或 REPLACE INTO。 INSERT IGNOR...
Post on 2016-12-19
1.25k
0
Python
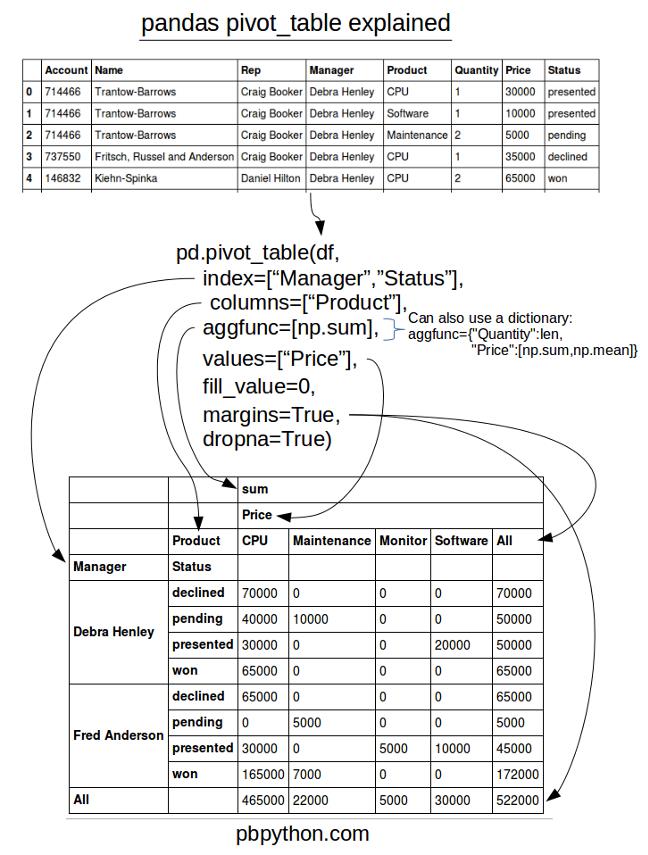
Pandas透视表(pivot_table)
pandas透视表有它独有的魅力。怎么用,这里有一篇好文,看完就会有一定的了解。 http://python.jobbo...
Post on 2016-11-08
808
0
Python
pandas中时间的计算
在pandans中,时间的计算以及转换,有它自己独有一套API.对时间的数据类型也很讲究。比如打印出来都一样,可能它是字...
Post on 2016-11-04
834
0
Python
DataFrame重命名列
我们在做merge的时候,如果两个DataFrame中存在相同的列名,merge会自动给相同的列名加上后缀。然后,你对需...
Post on 2016-11-04
808
0
Python
写数据到csv中
除了通过open的方式,打开csv文件,然后再write数据外。还可以通过pandas的read_csv方法打开csv文...
Post on 2016-10-28
788
0
Python
padans小笔记,DataFrame列的简单操作
对DataFrame的各种处理太多太多。这里,只记录一点点,以便熟悉和记忆。利用where特性,去除特殊的行或赋值。利用...
Post on 2016-10-27
796
0
Python
sqlalchemy的使用
方法多少种?喜欢用哪种。增删改查怎么做。
Post on 2016-10-26
739
0
Python
ip数据类型转换
在数据库中,怎么存储ip地址呢。是要追求可读性,存储效率,还是查询效率。可以喵喵这篇文章:http://www.cnbl...
Post on 2016-10-26
974
0
1
2
2026年 7月
一
二
三
四
五
六
日
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
« 9月
近期文章
laravel redis 使用
wordpress 日志历史草稿清除
WordPress 自动给文章的关键词添加链接 Links Auto Replacer
wordpress站点地图工具
唯你秀,官方9696-全网最有趣最专业的两性情感频道,你的个人情感咨询专家
分类
AIR
Air for ios.
AS3-Tool
AS3-点点滴滴
Away3D
C#
Flex
FMS 流媒体
H5
Javascript & Node.js
Nape
NUI
Other
Photoshop
PHP-积累点滴
Python
Starling
Swift
WordPress 点点滴滴
工具
微信公众平台
框架
璀璨傷城
系统点滴
音视频
归档
2019年9月
2017年6月
2017年4月
2017年3月
2017年2月
2017年1月
2016年12月
2016年11月
2016年10月
2016年9月
2016年8月
2016年7月
2016年6月
2016年5月
2016年4月
2016年3月
2016年2月
2016年1月
2015年11月
2015年10月
2015年9月
2015年8月
2015年7月
2015年6月
2015年5月
2015年4月
2015年3月
2014年12月
2014年11月
2014年10月
2014年9月
2014年8月
2014年6月
2014年5月
2014年4月
2014年3月
2014年2月
2014年1月
2013年12月
2013年11月
2013年10月
2013年9月
2013年8月
2013年7月
2013年6月
2013年2月
2013年1月
2012年12月
2012年11月
2012年10月
2012年6月
2012年5月
X